
3rd Workshop on Urban Scene Modeling — TBD (June 3 or 4), Full Day
Structured, Semantic, and Synthetic 3D Habitats (USM3D) - CVPR 2026
The 3rd Urban Scene Modeling (USM3D) Workshop at CVPR 2026 focuses on methods that reconstruct, structure, and semantically organize real-world built environments from heterogeneous visual and 3D data. We emphasize scene representations that move beyond raw point clouds and meshes toward high-level, editable, and task-ready models.
Following the success of the 2024 and 2025 editions, USM3D 2026 aims to bridge state-of-the-art 3D scene modeling with structured, semantic 3D reconstruction by bringing together researchers across photogrammetry, computer vision, generative models, learned representations, and computer graphics. The workshop includes invited talks, a peer-reviewed paper track, and public challenges on large-scale urban datasets to support benchmarking, reproducible pipelines, and integration across vision, graphics, photogrammetry, and 3D learning.
News
- March 13, 2026: Competitions started! 🎉
- December 22, 2025: 2026 proposal accepted! 🎉
Keynote Speakers
Florent Lafarge

Florent Lafarge: Researcher, Inria
Florent Lafarge is a researcher at Inria in the Titane research group. His research spans computer vision, geometry processing, and remote sensing. He works on the analysis and geometric modeling of 3D environments from physical measurements, typically multi-view imagery and laser scanning. His favorite topics include surface reconstruction and approximation, city modeling, piecewise-planar geometry, and spatial point processes.
Matthias Nießner

Matthias Nießner: Professor, Technical University of Munich; Founder, Synthesia; SpAItial
Matthias Nießner is a Professor at the Technical University of Munich, where he leads the Visual Computing Lab. His work spans computer vision, graphics, and machine learning, focusing on 3D reconstruction, scene understanding, and AI-based video synthesis. He has authored 150+ papers and co-founded Synthesia Inc. and SpAItial to develop foundational models for 3D world understanding and generation.
Angel Xuan Chang

Angel Xuan Chang: Associate Professor, Simon Fraser University
Angel Xuan Chang's research focuses on connecting language to 3D representations of shapes and scenes and grounding language for embodied agents in indoor environments. She has worked on methods for synthesizing 3D scenes and shapes from natural language, and on datasets for 3D scene understanding.
Renzhong Guo

Renzhong Guo: Professor, Shenzhen University
Renzhong Guo is a professor and head of the Research Institute for Smart Cities at Shenzhen University. He has authored four monographs and published over 100 papers. His work has been recognized with multiple national and provincial awards in science and technology progress.
Unreleased

Coming soon
More exciting speakers will be announced in the coming days / weeks!
Call for Papers
We invite submissions of original research related to structured, semantic, and synthetic 3D reconstruction and modeling of human environments. Topics of interest include, but are not limited to:
- Structured 3D reconstruction/modeling of human environments from sparse, noisy, or partial point clouds and images
- Semantic, instance, and panoptic segmentation and parsing of 3D point clouds and images
- Fusion of images and point clouds to improve structure of human-centric 3D scene modeling
- Structured representations of 3D scenes (e.g., CAD, B-Rep, wireframe, procedural models)
- Learning priors for structured 3D modeling and structural consistency
- Generative models for image generation and realistic textures
- Intersection of world models and 3D reconstruction for realistic generation with sparse 3D
- Multiview 3D matching and registration for complex spaces
- Pose estimation and structured 3D recovery from sparse image sets
- Differentiable rendering and occlusion reasoning in human environments
- Cross-disciplinary influence of 3D representations for built environments
- Benchmarks and datasets for large-scale 3D modeling of human environments
We will accept submissions on two tracks: extended abstracts (≤4 pages) and full papers (≤8 pages) in the standard CVPR format. Accepted submissions will be presented as posters, and some will be selected for spotlight talks.
Where to Submit
Submission site: https://cmt3.research.microsoft.com/USM2026
Important Dates
- Paper submission deadline: March 24, 2026 (Anywhere on Earth)
- Notification to authors: April 1, 2026
- Camera-ready deadline (to USM3D): April 8, 2026
Challenges
S23DR Challenge (HoHo)
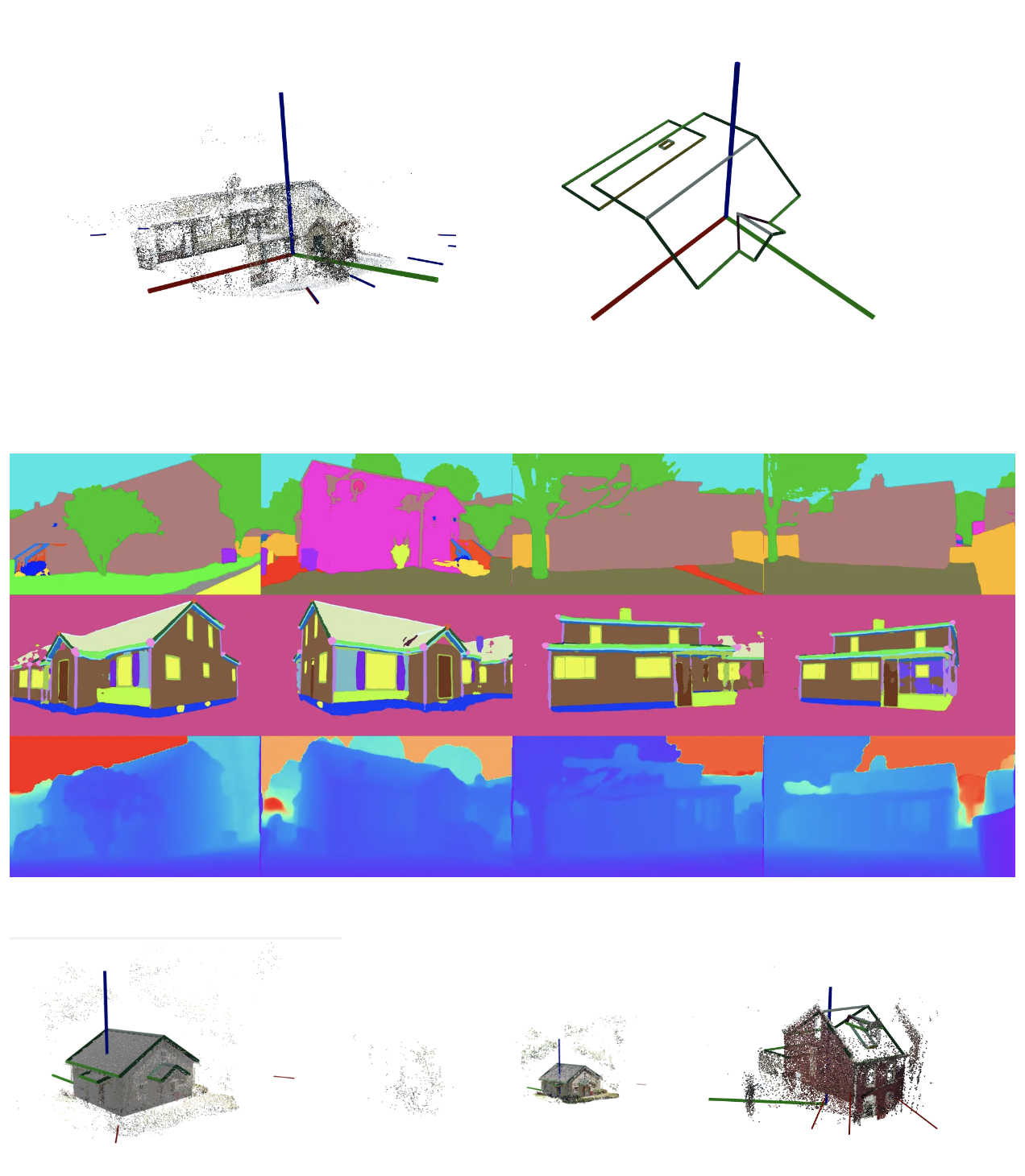
The S23DR challenge involves recovering 3D models with structural details from multi-view images captured at ground level via mobile devices. The HoHo dataset consists of 26k anonymized US house exteriors with structured annotations, wireframes, sparse point clouds, camera poses, and derived semantic signals. Raw images are not released due to licensing and privacy constraints.
Evaluation
Participants output a spatial graph for each challenge, with edge semantics defined by neighboring faces. As in 2024 and 2025, evaluation takes place on a private HuggingFace server using separate test sets for public and private leaderboards. The Hybrid Structure Score metric will be used for evaluation.
Important Dates
March 13, 2026: Dataset release and competition start
May 25, 2026: Submission deadline
Winners announced: At workshop
Prize fund: $12 000
Dataset: HoHo2026
Competition: S23DR 2026
Building3D Challenge
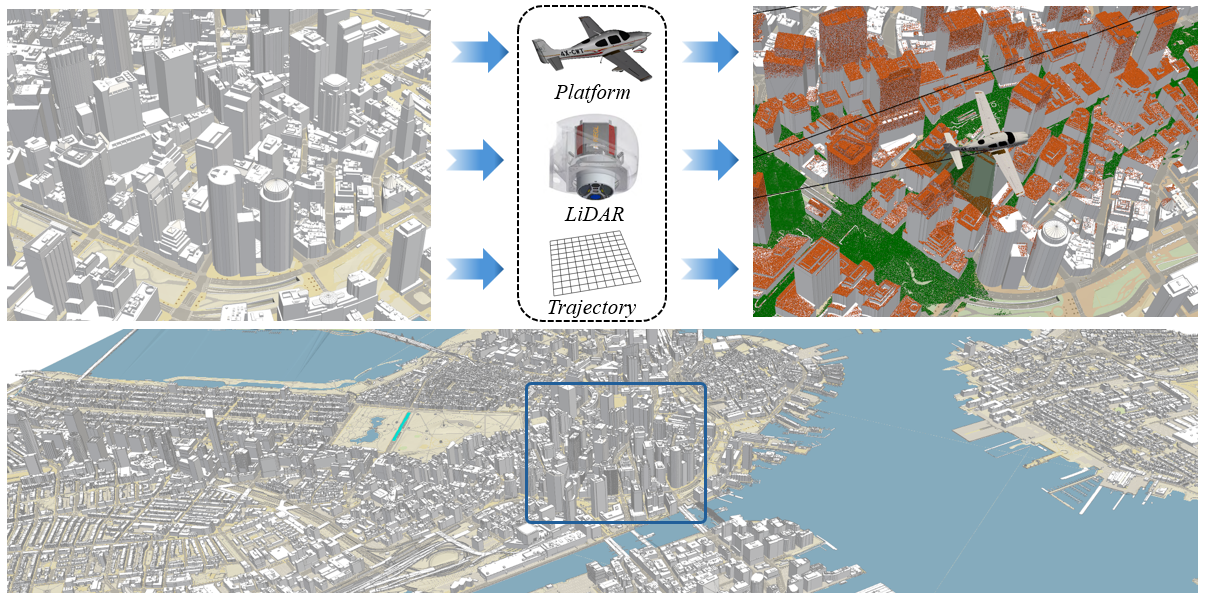
We are delighted to announce that the Building3D Challenge, held as part of the 3rd USM3D Workshop, will feature a newly released dataset—BuildingWorld. BuildingWorld is a comprehensive and structured 3D building dataset designed to bridge the gap in stylistic diversity. It encompasses buildings from geographically and architecturally diverse regions—including North America, Europe, Asia, Africa, and Oceania—offering a globally representative dataset for urban-scale foundation modeling and analysis. Specifically, BuildingWorld provides about five million LOD2 building models collected from diverse sources, accompanied by real and simulated airborne LiDAR point clouds.
In this challenge, participants are expected to train or build their models using the BuildingWorld dataset. All submissions must be made through the Hugging Face platform. The total prize pool remains at $2 000, and only submissions that outperform the baseline method will be considered for monetary awards.
Important Dates
March 13, 2026: Dataset release and competition start
May 25, 2026: Submission deadline
Winners announced: At workshop
Datasets: BuildingWorld and HuggingFace BuildingWorld
Competition website: Building3D Challenge 2026
Sponsorships
We are actively recruiting sponsors (including corporate and institutional partners). If you are interested in sponsoring USM3D 2026, please email usm3d@jackml.com.
Organizers
 Ruisheng
Ruisheng Wang Professor
Shenzhen University
Professor at Shenzhen University with research in photogrammetry and computer vision, focused on large-scale urban modeling. Recipient of ISPRS Samuel Gamble Award and multiple industry awards.
 Jack
Jack Langerman Applied Researcher
Apple
Applied researcher at Apple focused on interpretability, steerability, and alignment. Previously led structured geometry research at Hover and founded the Generative Machine Learning Group.
 Dmytro
Dmytro Mishkin HOVER Inc. / FEE, Czech Technical University in Prague
Researcher at HOVER and Czech Technical University in Prague.
 Ilke
Ilke Demir Founder & CEO
Cauth AI
Founder and CEO of Cauth AI, previously at Intel Labs. Her work spans proceduralization of 3D data, trusted media, and generative research in graphics and vision.
 Tolga
Tolga Birdal Assistant Professor
Imperial College London
UKRI Future Leaders Fellow researching geometric machine learning and 3D computer vision, with a focus on geometric inference and learning.
 Sean (Xiang)
Sean (Xiang) Ma Head of Research
Amazon Web Services
Head of research and senior applied science manager at AWS, with extensive experience in mapping, localization, and autonomous driving.
 Yang
Yang Wang Associate Professor
Concordia University
Associate professor at Concordia University with prior roles at University of Manitoba and Huawei Canada as chief scientist in computer vision.
 Shangfeng
Shangfeng Huang Researcher
University of Calgary
Researcher focusing on 3D building reconstruction from aerial point clouds for digital twins, with expertise in wireframe and B-rep reconstruction.
 Yuzhong
Yuzhong Huang Senior CV Engineer
HOVER Inc.
Senior computer vision engineer at HOVER with research interests in CAD reconstruction from sensor data and images. Co-organized USM3D 2025.
Links
This is a CVPR 2026 workshop
The Microsoft CMT service was used for managing the peer-reviewing process for this conference. This service was provided for free by Microsoft and they bore all expenses, including costs for Azure cloud services as well as for software development and support.